Data Quality Engineering at EY
TL;DR: I designed and built a scalable Python engine to automate data quality validation for a major financial client. My core contribution was a multi-state validation process that proved most data errors were simple formatting issues, not factual inaccuracies, saving significant manual review time.
This project was completed under the guidance of Arpit Tejan (Data Science Manager) and Parth Behl (Consultant).
Disclaimer: To protect client confidentiality, all data, field names, and business domains shown in the following visuals are representative examples created to demonstrate the tool's architecture and impact.
Project Highlights
Architected a Scalable Rule Engine
Designed a system to process gigabytes of historical data, validating millions of records against 125+ business rules using a decoupled Python and JSON architecture.
Engineered a Reusable Function Library
Normalized 800+ unstructured business requirements into ~30 core, reusable Python functions, making the system highly maintainable.
Pioneered Multi-State Validation
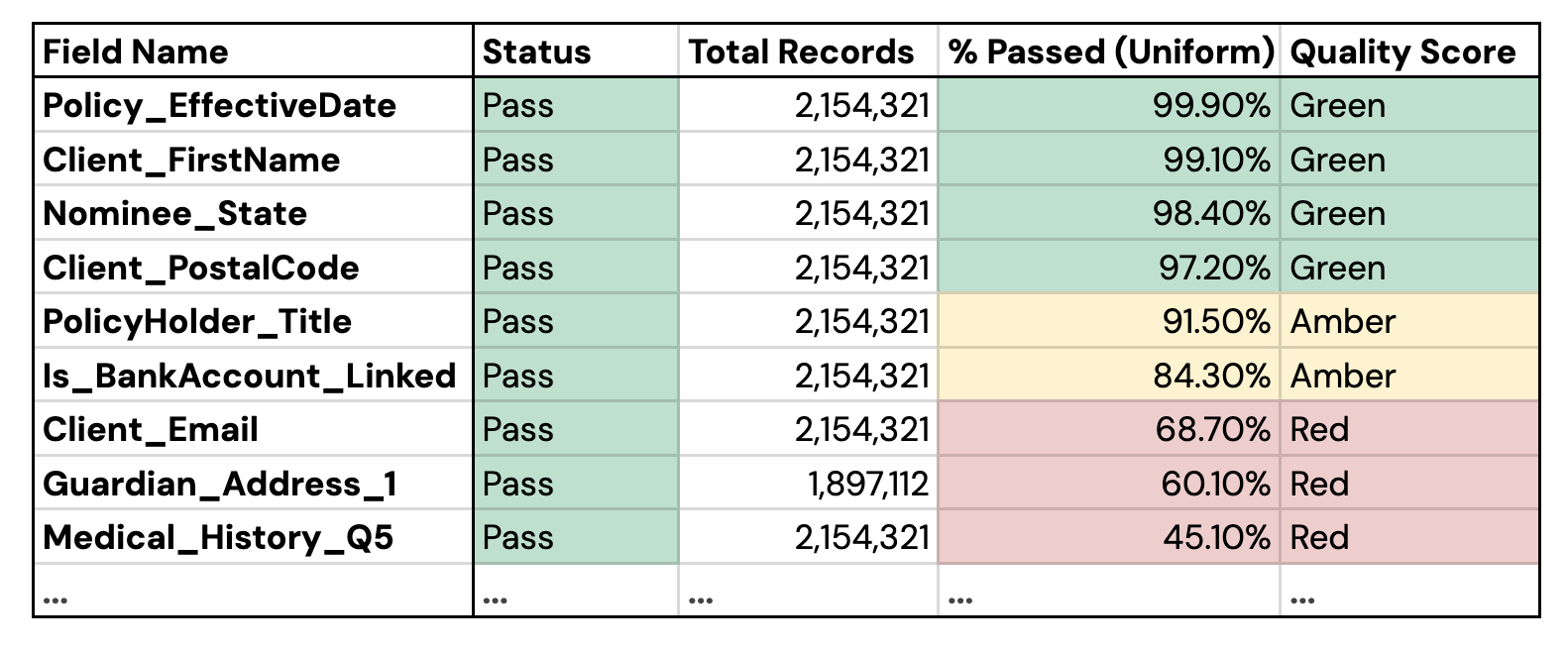
My core idea: testing data as-is, trimmed, and uniform proved most errors were simple formatting issues, not factual inaccuracies.
Automated Reporting & Visualization
Built an automated pipeline that generated reports with visualizations (pie/bar charts) and a color-coded scoring system, surfacing 87% of critical DQ issues to make results actionable.
1. The Challenge & A New Direction
The initial challenge was immense: the business had poor data quality, but the reasons were unclear, and the rules for validation were scattered across unstructured documents. In the project's foundational phase, I took the initiative to establish a more strategic direction, advocating for a shift away from writing a separate function for every single rule. I guided my team towards an approach centered on creating a library of reusable, generalized functions. This pivot set the stage for the highly efficient and scalable system that followed.
2. A Decoupled, Scalable Architecture
Realizing that a simple script would be unmanageable, I took the lead in designing a fully-fledged, scalable system. To ensure the solution was robust, I designed a decoupled architecture where the rule logic (`rules.json`), field mappings (`map.json`), and the core validation script were separated. This design was a key proposal of mine, ensuring that new rules and data sources could be added in the future without changing the core engine code.
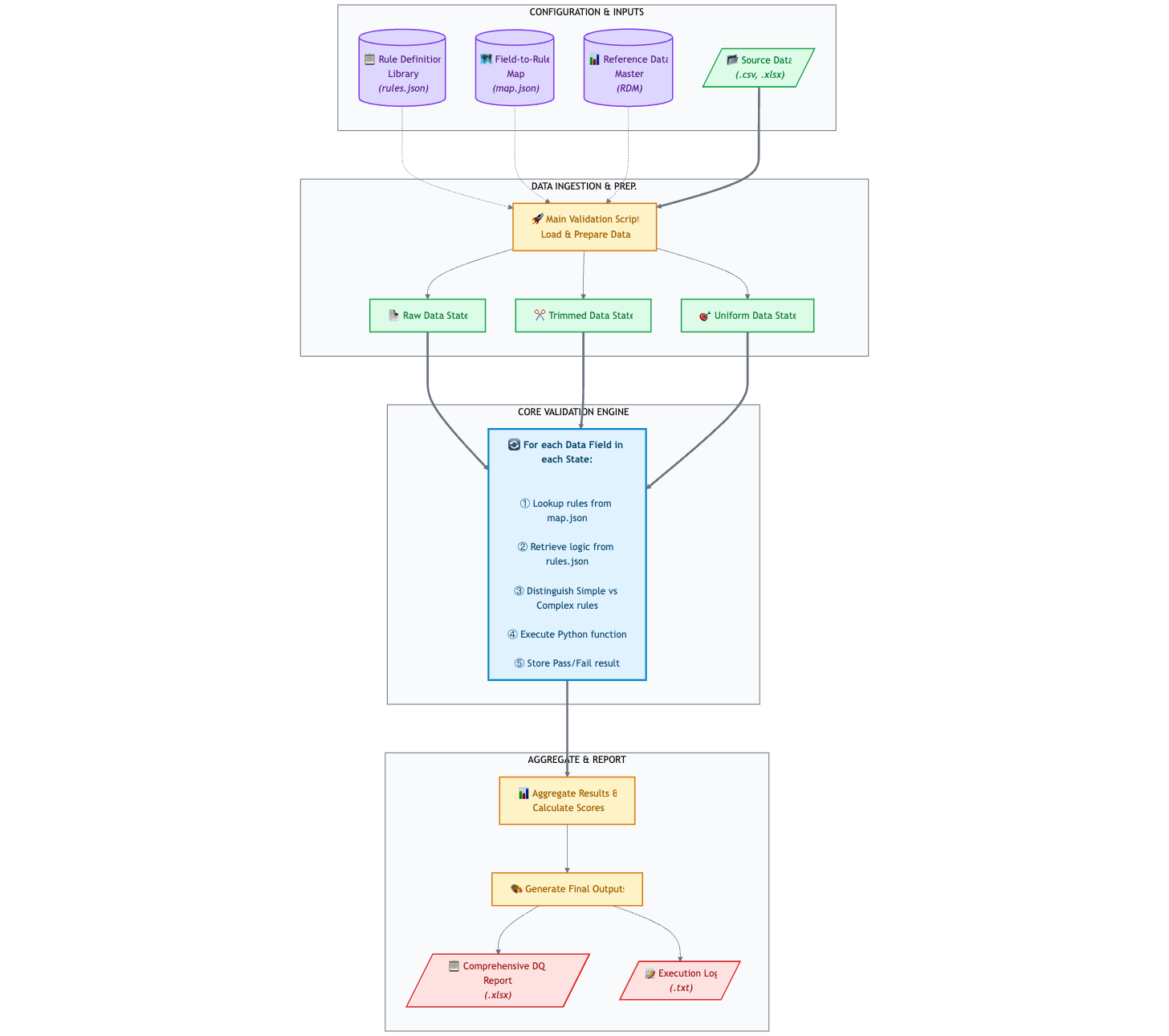
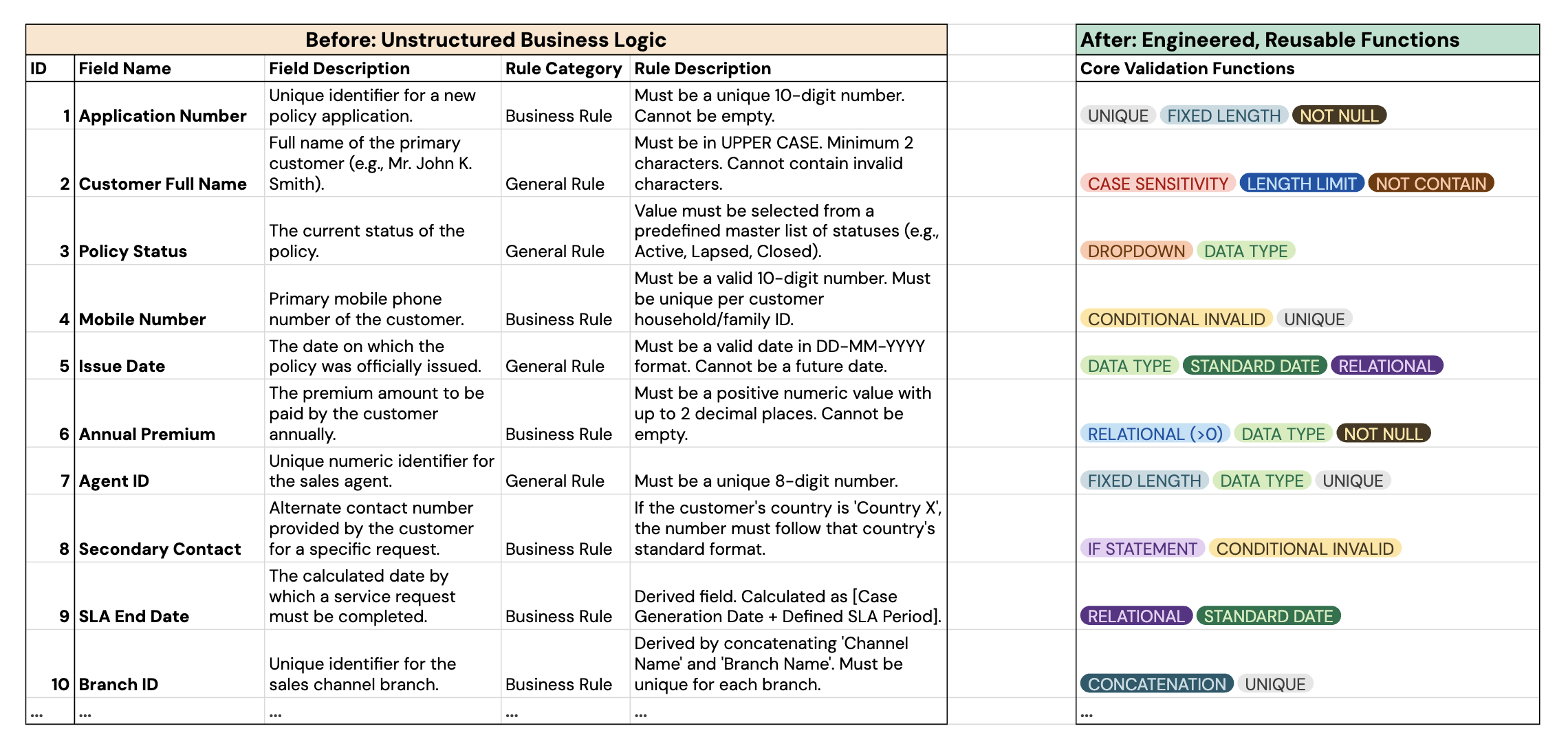
3. From Chaos to Code
The most critical part of my design was creating the reusable rule architecture. I led a team of three to analyze over 800 ambiguous, text-based business rules and normalized them into a modular set of ~30 reusable Python functions. This strategy transformed vague requirements into a structured, machine-readable format that was both efficient and easy to maintain.
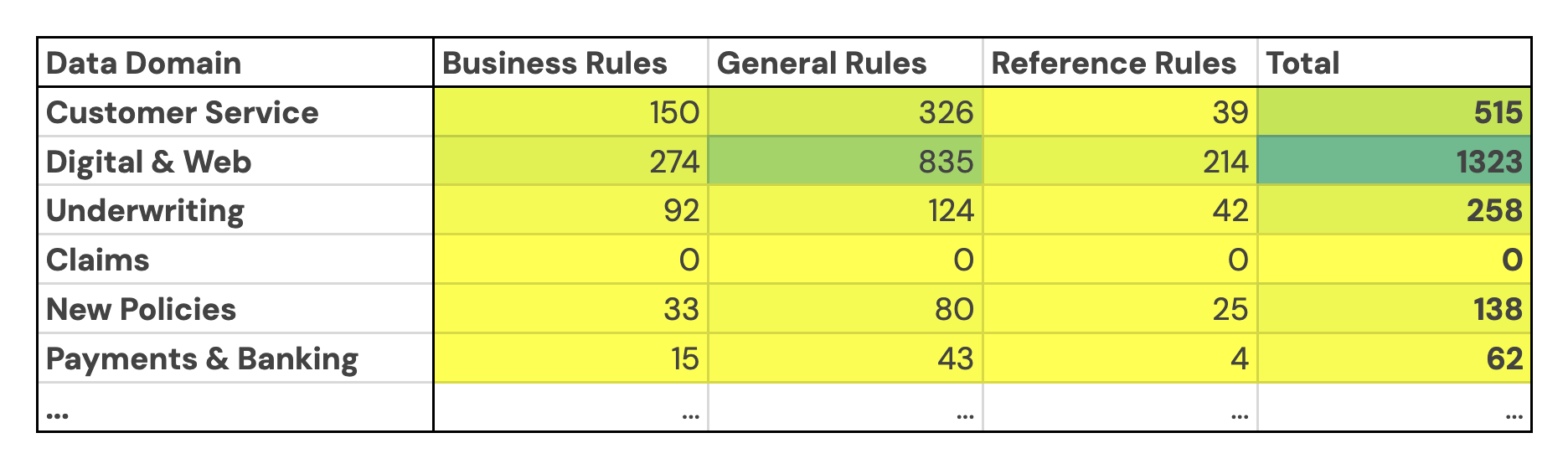
This normalized rule engine was then applied across more than 15 distinct business domains, providing a comprehensive, enterprise-wide view of data quality.
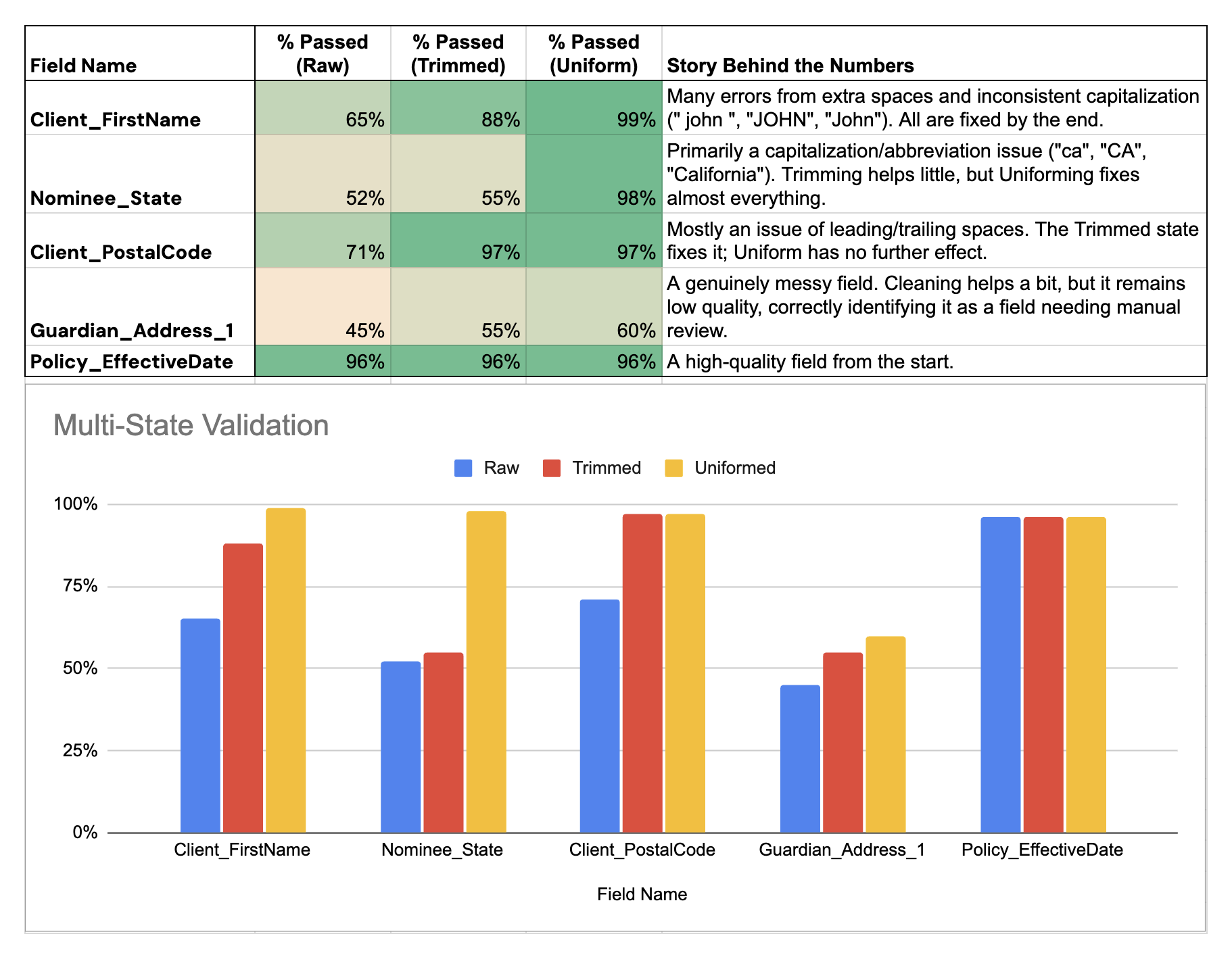
4. The Core Insight
My central hypothesis was that many "errors" were merely formatting issues. To test this, I pioneered a multi-state validation check within the tool that tested each field three times: as-is (Raw), with whitespace removed (Trimmed), and with standardized capitalization (Uniform). The results were transformative and proved my hypothesis correct.
5. Impact and Handover
The project's most significant outcome was a paradigm shift in how the organization understood data quality. The stakeholders could clearly distinguish between "unclean" data (formatting issues) and truly "inaccurate" data (factual errors). This allowed the business to focus their expert reviewers only on the genuinely inaccurate data.
Towards the end of my internship, I led the project handover to two other developers, working with them to refactor the code for long-term efficiency and ownership. This ensured the tool I built would continue to provide value long after my internship concluded.