DocuSense: Intelligent PDF Management
An end-to-end project where I designed and engineered a smart document tool to turn digital clutter into an organized, queryable library using data science and machine learning.

1. The Challenge: Taming Digital Chaos
As a student, I was dealing with a growing collection of disorganized PDFs—lecture notes, research papers, and personal documents. Finding a specific file was often a frustrating, time-consuming process.
This "digital clutter" leads to inefficient search and wasted storage. I saw an opportunity to build a tool that doesn't just store PDFs, but understands them.

2. The Process: From Idea to Prototype
I approached this project with a dual mindset: as a Product Manager defining the "what" and "why," and as an Engineer building the "how."
Product Thinking & Design
I started by defining the user pain points, brainstorming core features, and designing a clean UI in PowerPoint to make the functionality feel simple and accessible.
Technical Implementation
I built the data analysis pipeline using Pandas and PyPDF2. To enable the core features, I implemented:
- MD5 Hashing for efficient duplicate detection.
- TF-IDF & Cosine Similarity to engineer a content-based search engine with Scikit-learn.
- K-Means Clustering to automatically group similar documents based on their content vectors.
- OCR Integration with Pytesseract to extract text from scanned PDFs.
3. The Solution: DocuSense in Action
The result is a practical PDF management tool built on a foundation of data science. The prototype delivers three core features:
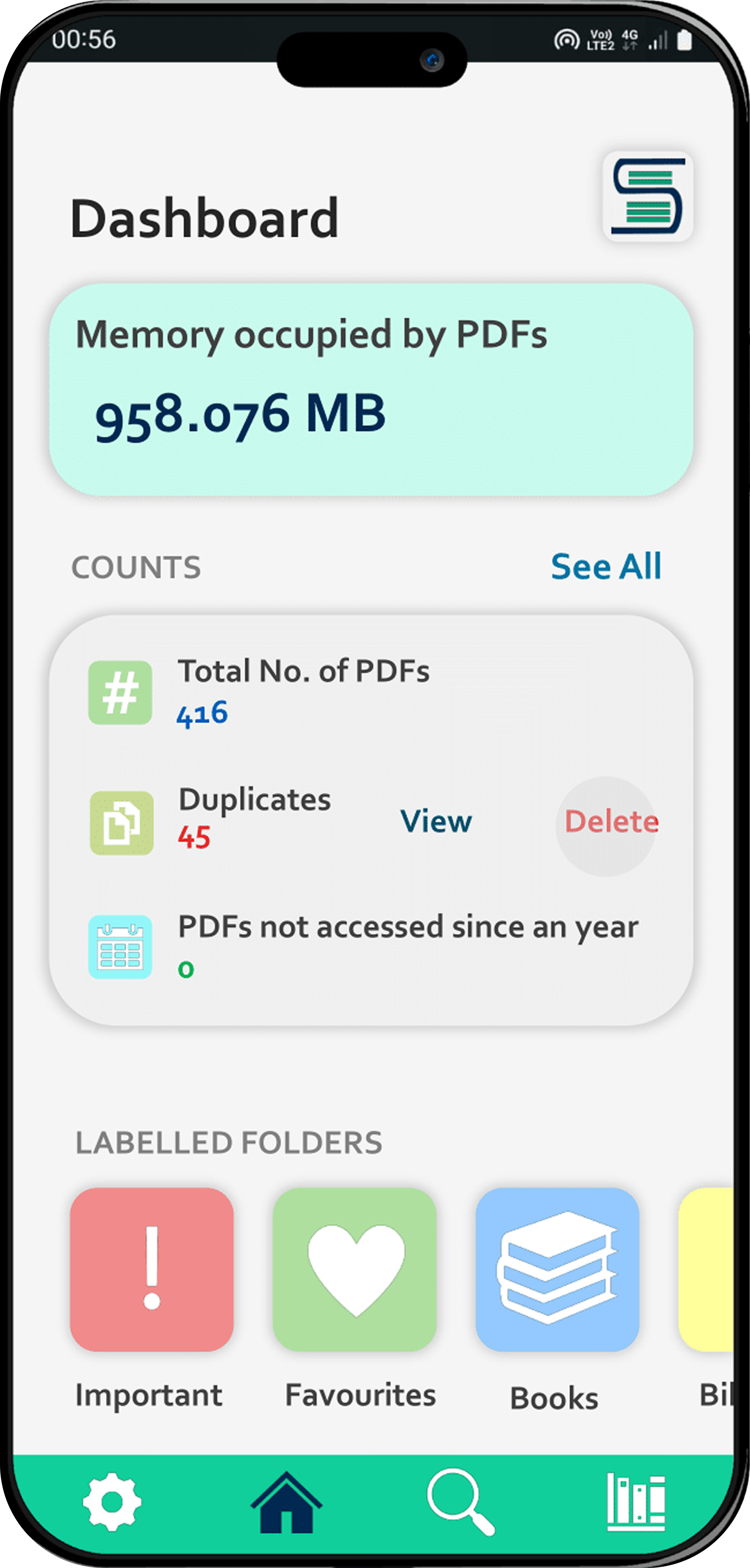
Analytics Dashboard
Instant insights on your entire PDF collection.
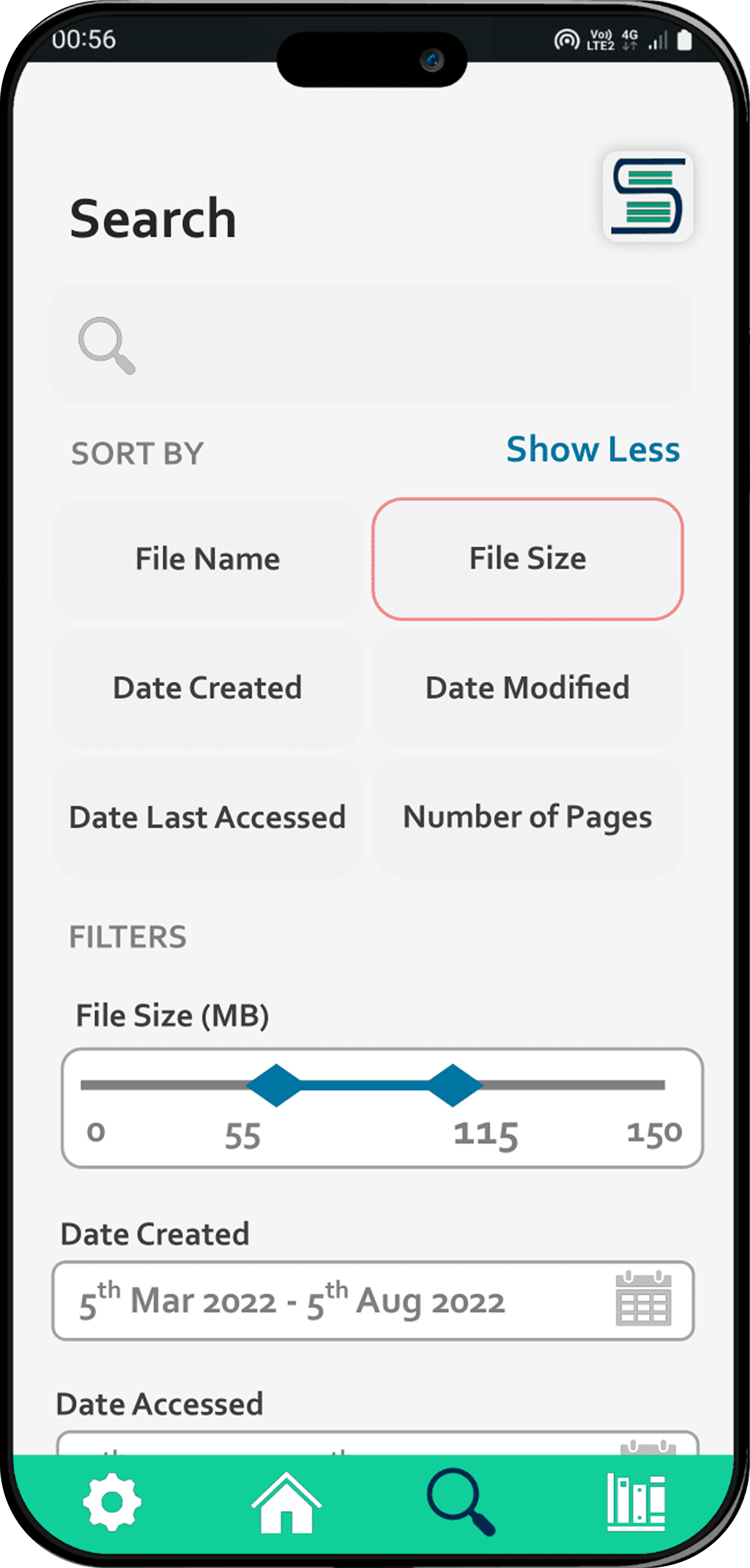
Content-Based Search
Find files by what's inside them, not just by name.
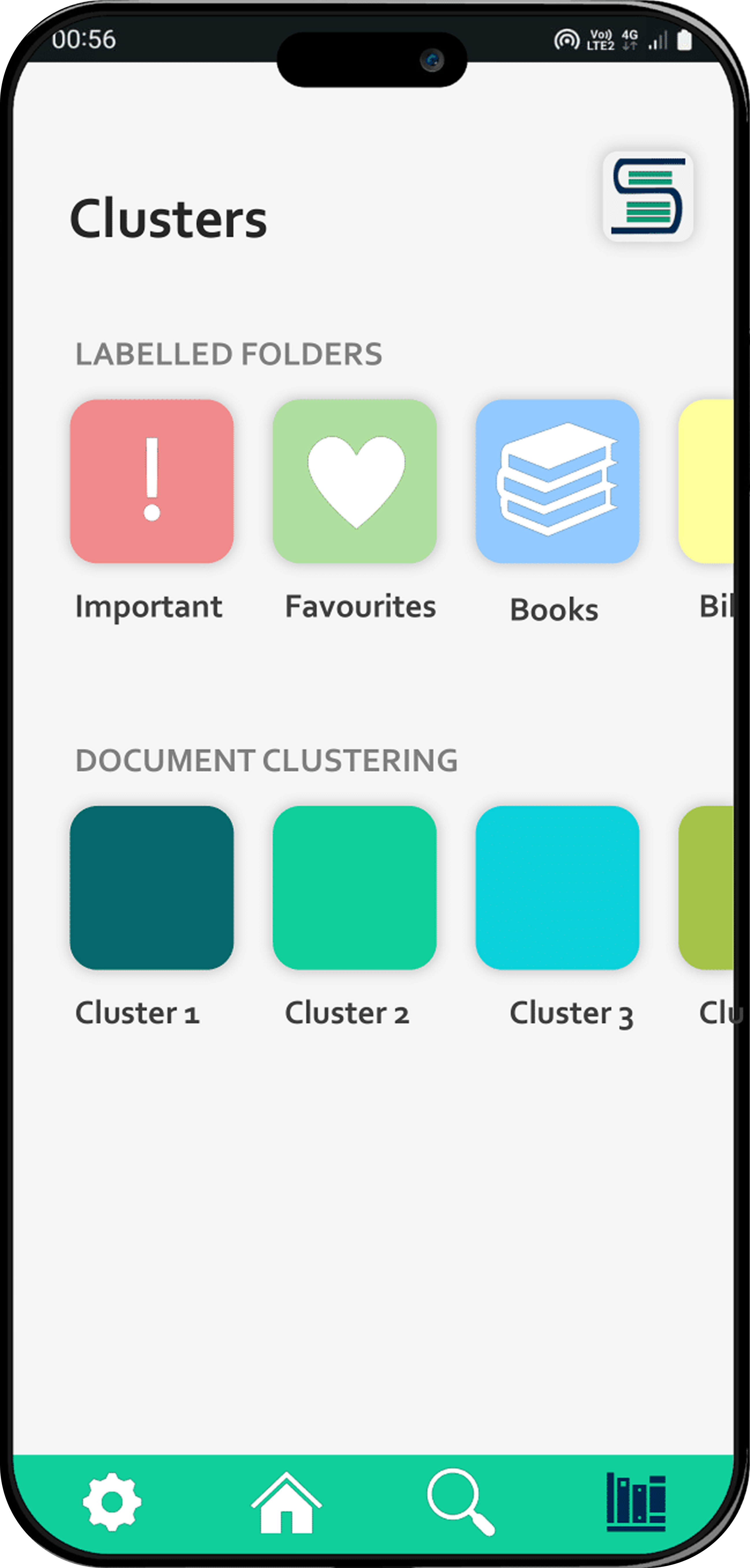
Intelligent Clustering
Automatically groups similar documents together.
4. Future Scope & Learnings
This project was a valuable exercise in building a solution from the ground up. It provided a solid foundation, and the clear next steps for expanding its capabilities would be:
- Text Summarization: Integrate a transformer model to provide quick summaries.
- Supervised Classification: Use user-generated labels to train a model for smarter, personalized tagging.
- Cloud Storage Integration: Connect directly to Google Drive, Dropbox, and OneDrive.